CSSセレクターマッチングのコスト
ブラウザエンジン先端観測会での、Constellationさんの話を聴いて、CSSセレクターマッチングのコストには複数のレベルがあることを強く意識するようになりました。セレクターマッチングにかかるコストを下げたい、という場合には、どのレベルで何を高速化しようとしているのかを意識しないと話がかみあいません。Constellationさんの話を私なりに整理して考えた、セレクターマッチングのコストを下げるアプローチは次の3つです。
- ①セレクターを減らす
- ②マッチするかどうかの判定回数を減らす
- ③1回1回の判定処理を速くする
これは、ブラウザーのセレクターマッチングの処理の各部分に対応しています。
この記事の残りでは、Constellationさんの話を私なりに整理した結果を書きます。ですので、ブラウザエンジン先端観測会でのConstellationさんの話以上の知見はありません。
- CSS JIT: Optimizing CSS Selector Matching with Just-in-Time Compilation
- ブラウザエンジン先端観測会 アウトラインメモ
- ブラウザエンジン先端観測会 #1
①セレクターを減らす
ブラウザーはCSSに記述されている各セレクター*1について、対象となる要素すべてにマッチするかどうかの判定を行います。多くの場合、「対象の要素すべて」はページ内の全要素になります。
また、WebKitは、「セレクターの中に#idがあるのでまず#idの子孫を絞り込んでからマッチする要素を探す」といった処理を行わないとのことです。愚直にすべての要素を対象にマッチするかどうかの判定を行うとのことです。Constellationさんによるとdocument.querySelector の実装である SelectorQuery.cpp の方で事前に filtering を行うことによって, この #id が含まれるケースの絞り込みが行われています
とのことです。詳しくはコメントを参照してください。
さらに、Constellationさんによると、WebKitは、セレクターが矛盾していない限り*2、すべてのセレクターについてマッチング処理を行うとのことです。
以上を踏まえると、WebKitはセレクターが100個記述されていると100回処理します。これも単純に100回処理するのではなく、(100×ページ内の全要素数)回処理をします。しかも、後で見るように、1つの要素がセレクターにマッチするかどうかの判定が1回で終わるとは限りません。仮にページ内に要素が100個あり、判定処理を平均10回行うとすると、100セレクターでは100×100×10=100000回(10万回)の処理が発生します。一方、同じ条件でセレクターを1つにできれば、1×100×10=1000回の処理で済みます。これが①セレクターを減らす、の意味です。
②マッチするかどうかの判定回数を減らす
セレクターの数を変えられない場合には、ある要素がセレクターにマッチするかどうかの判定回数を下げるというアプローチがあります。ブラウザーは
- セレクターそれぞれについて(①)、
という処理をしているので、②の処理が小さくなるようにセレクターを調整します。そのためにはブラウザーの処理を考える必要があります。ブラウザー先端観測会ではこの部分が丁寧に解説されました。
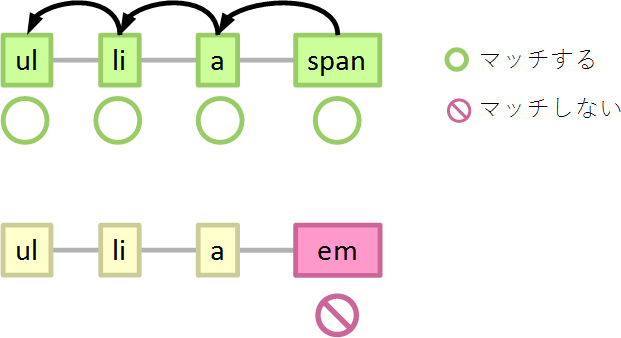
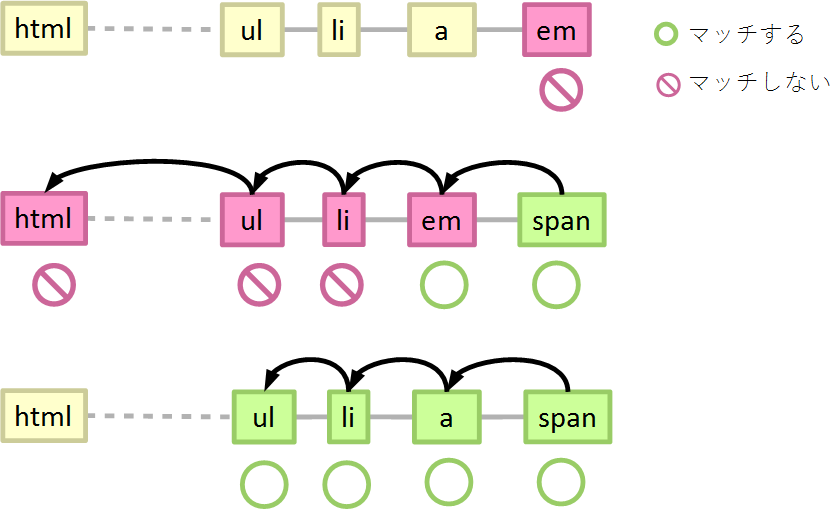
ブラウザーはある要素がセレクターにマッチするかしないかを、セレクターの右から評価していきます。
ul > li > a > span { }
と書いてあれば、ページの中の要素の1つ1つに対して、
- spanにマッチするか…マッチしたら親要素を辿る、しなければ終了
- aにマッチするか…マッチしたら親要素を辿る、しなければ終了
- liにマッチするか…マッチしたら親要素を辿る、しなければ終了
- ulにマッチするか…マッチしたら終了、しなくても終了
という順番に判定していきます。となると、マッチするかどうかの判定が4回かかるセレクターよりも、1回で済むセレクターの方が、マッチングのコストが小さそうです(早く処理を終えることが期待できます)。
span { }
- spanにマッチするか…マッチしたら終了、しなければ終了
また、ここで考えておきたいのは、セレクターが要素にマッチするときの処理だけが早くなっても効果は薄いだろうということです。というのも、あるセレクターにマッチする要素はページの中で少数派であることがほとんどだからです。しかし、セレクターマッチングはすべての要素に対して行われるので、マッチしない要素の方が多数派という状況が多く発生します。であるならば、少数派の処理時間だけではなく、多数派と少数派の両方の処理時間を考えた方が良いでしょう。例えば、ユーザーが選択中のタブにスタイルをあてるために、次のようなセレクターを書くとしましょう。
.tablist > li > a.selected { }
ページの中に選択中のタブが1個しかなければ、マッチするのは1回だけで、ほかの要素はマッチしません。ということは、処理時間の大半はマッチしない要素に費やされているでしょう。
以下では、マッチするかどうかの判定回数を減らすアプローチを考えていきます。Constellationさんの話では、親要素*3を辿って判定する回数は結合子(「 」「>」「+」「~」など)によって異なるということでした。そこで、以下では結合子ごとに考えます。
結合子なし(単純セレクターのみ)
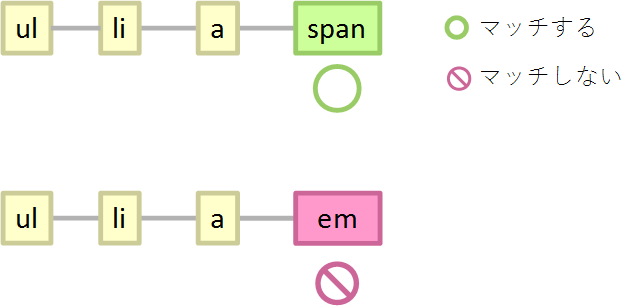
結合子なし(単純セレクターのみ*4)の場合、どんなに悪い状況でも、1つの要素につき1回しか判定しません。
span {}
対象となる要素すべて(ページ内のすべての要素)に対して1回だけマッチするかどうかの判定を行って、それでおしまいです。また、判定処理は0回にできないので、判定1回は最善の状況です。
子供結合子(E > F)しかない場合
子供結合子しか使わない場合は、どんなに悪い状況でも、1つの要素につき(子供結合子の数+1)回しか判定しません。
次の例を考えてみましょう
ul > li > a > span {}
この例は、一番悪い状況は対象要素がセレクターにマッチする場合で、4回判定します。
- spanにマッチするか…マッチしたので親要素を辿る
- aにマッチするか…マッチしたので親要素を辿る
- liにマッチするか…マッチしたので親要素を辿る
- ulにマッチするか…マッチしたので終了
逆に、一番良い状況は、セレクターの一番右が対象要素にマッチしない場合です。
- spanにマッチするか…マッチしなかったので終了
これは1回しか判定を行わないので、結合子なしと同じ最善の状況です。まあまあな状況では、セレクターの一部にマッチする要素について、2回もしくは3回マッチするかどうかの処理を行います。
以上を踏まえると、子供結合子しか使わない場合に、親要素を辿る処理を減らすには、次のようなアプローチが考えられます。
- 子供結合子の数を減らす
- 子供結合子の右に、マッチ頻度が低い単純セレクターを記述
子供結合子の数を減らす
子供結合子しか使わない場合、どんな状況でも(子供結合子の数+1)回より多く判定を行うことはないわけですから、結合子の数が減ればそれだけで状況は改善します。
ul > li > a > span {} /* A */
ul > li > a { } /* B */
Aでは、最悪(マッチ)は4回判定、まあまあ(部分的にマッチ)が2~3回判定、最善(完全にマッチしない)が1回判定ですが、Bでは、最悪(マッチ)は3回判定、まあまあ(部分的にマッチ)が2回判定、最善(完全にマッチしない)が1回判定になりました。
子供結合子の右に、マッチ頻度が低い単純セレクターを記述
子供結合子の右に、マッチする要素がページに出現する頻度が低いセレクターを記述するアプローチは、親要素を辿りにいく要素を減らすことを意図しています。このアプローチでは最悪の場合は改善できませんが、それ以外の状況は改善できるでしょう。
例えば、次のようなセレクターを考えてみましょう。
ul > li > a > span { } /* A */
ul > li > a > span#foo { } /* B */
ページの中に、span要素が100個あったとしましょう。そのうち
- 親がa要素でないものが50個(α)
- 親がa要素であるものが50個
- 親がli要素でないものが49個(β)
- ul > li > a > span#foo にマッチするのものが1個(γ)
すると、Aでは、50個の要素(α)で2回判定、49個の要素(β)で3回判定、1個の要素(γ)で4回判定します。
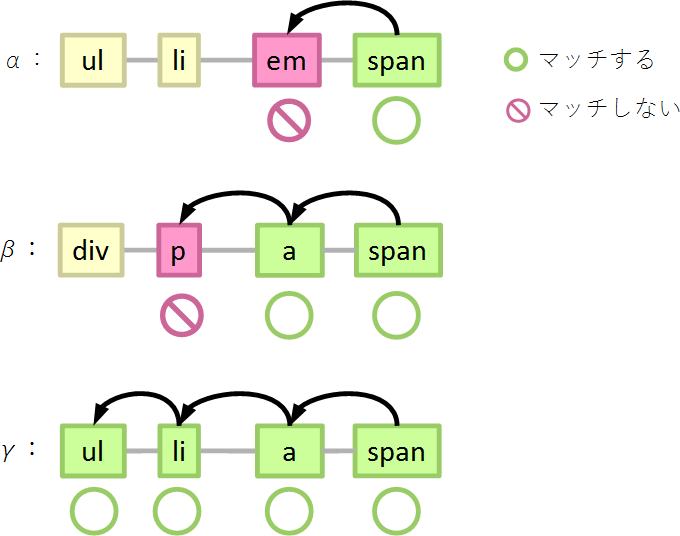
詳しく見ると、50個の要素(α:親がaでない)では、
- spanにマッチするか…マッチしたので親を辿る
- aにマッチするか…マッチしないので終了
49個の要素(β:親がaだが、aの親はliでない)では、
- spanにマッチするか…マッチしたので親を辿る
- aにマッチするか…マッチしたので親を辿る
- liにマッチするか…マッチしないので終了
1個の要素(γ)では、
- spanにマッチするか…マッチしたので親を辿る
- aにマッチするか…マッチしたので親を辿る
- liにマッチするか…マッチしたので親を辿る
- ulにマッチするか…マッチしたので終了
となります。
しかしBのセレクターでは、99個の要素(αとβ)で1回判定して終わり、1個の要素(γ)で4回判定して終わり、になります。
ul > li > a > span#foo { } /* B */
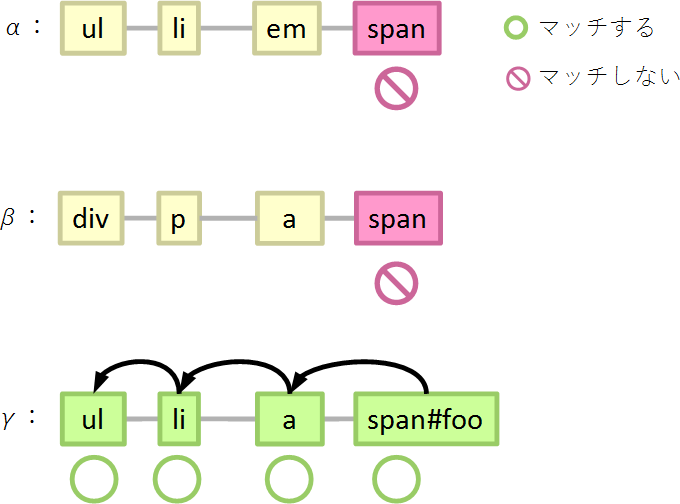
詳しく見ると、99個の要素(αとβ:spanがspan#fooでない)では、
- span#fooにマッチするか…マッチしないので終了
となります。
ブラウザーはセレクターを右から順番に評価する、ということは、左に進ませなければ、それだけ処理を早く終わらせることができます。左に進ませないようにするには、右側に出現頻度の低いセレクターを記述することです。
子供結合子しか使っていない場合は、出現頻度の低い単純セレクターをどの子供結合子の右に書いても、一定の効果が期待できます。次のような例を考えてみましょう。
ul > li > a > span { } /* A */
ul > li > a#foo > span { } /* C */
ここでもページの中に、span要素が100個あったとしましょう。そのうち
- 親がa要素でないものが50個(α)
- 親がa要素であるものが50個
- a要素にid属性が指定されていないものが49個(β)
- ul > li > a#foo > span にマッチするのものが1個(γ)
とします。
Aでは、50個の要素(α)で2回判定、49個の要素(β)で3回判定、1個の要素(γ)で4回判定します。しかし、Cでは、99個の要素(αとβ)で2回判定して終わり、1個の要素(γ)で4回判定して終わり、になります。
99個の要素(αとβ:親がa#fooでない)では
- spanにマッチするか…マッチしたので親を辿る
- a#fooにマッチするか…マッチしないので終了
となるためです。
さすがにここまで極端な記述はできないと思いますが、子孫結合子だけを使う場合、セレクターの右側にマッチしにくいものを記述することで、親要素を辿って判定する処理を減らすことができます。
子孫結合子(E F)を使う場合
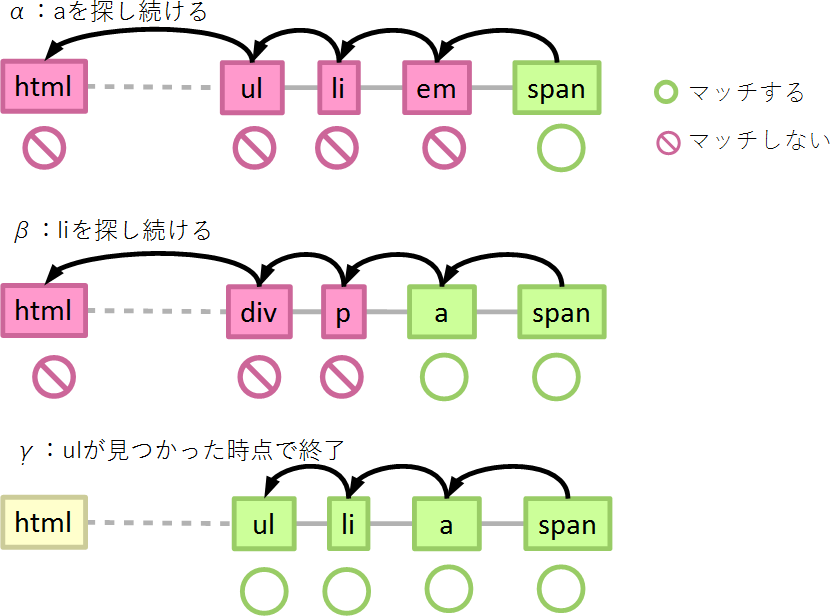
子孫結合子を使う場合は、やや複雑です。これも次の例を使って考えてみましょう。
ul li a span {}
まず、最善の場合です。子孫結合子を使う場合の最善の場合は、一番右の子孫結合子の右に記述されているセレクター(span)に要素がマッチしない場合です。
- spanにマッチするか…マッチしないので終了
子孫結合子の右にマッチしなければ、そこで処理は終了するので、1回*5しか判定しません。
最悪の場合は、セレクターの一部がマッチするが、全体としてはマッチしない要素です。この例の場合には、a要素に含まれないspan要素などが該当します。a要素に含まれないspan要素を考えると、
- spanにマッチするか…マッチしたので親要素を辿る
- aにマッチするか…マッチしないので親要素を辿る
- (ルート要素まで親要素を辿って判定する処理を繰り返し)
- ルート要素はaにマッチするか…マッチしないので親要素を辿る…ルート要素には親要素がないので終了
子孫結合子の左にマッチする要素が存在しないことを確かめるには、祖先を全て確認しないといけないため、親要素を辿る処理が増えます。存在する場合には、親要素を辿っている途中で見つかるので、全て確認しなくても処理は終わります(まあまあの場合)。
ここでも例を考えてみましょう。
ul li a span {}
やはりページの中に、span要素が100個あったとしましょう。そのうち
- 祖先にa要素が存在しないものが50個(α)
- 祖先にa要素が存在するものが50個
- a要素の祖先にli要素が存在しないものが49個(β)
- ul li a span にマッチするのものが1個(γ)
また、話を簡単にするためにspan要素の祖先要素の数はすべて9としましょう。この場合、99個の要素(αとβ)で10回判定、1個の要素(γ)で4~10回判定します。
詳しく見てみると、50個の要素(α:祖先にaが存在しない)では
- spanにマッチするか…マッチしたので親要素を辿る
- 1個上の要素はaにマッチするか…マッチしないので親要素を辿る(aを探す)
- …
- 9個上の要素(ルート要素)はaにマッチするか…マッチしないので親要素を辿ろうとしても親要素はないので終了
の10回判定を行います。
49個の要素(β:祖先にliが存在しない)でも
- spanにマッチするか…マッチしたので親要素を辿る(aを探す)
- …
- n個上の要素はaにマッチするか…マッチしたので親要素を辿る(liを探す)
- …
- m個上の要素はliにマッチするか…マッチしないので親要素を辿る(liを探す)
- …
- 9個上の要素(ルート要素)はliにマッチするか…マッチしないので親要素を辿ろうとしても親要素はないので終了
の10回判定処理を行います。
このように、子孫結合子を使った場合、セレクターの一部にマッチして全体がマッチしない要素では、ルート要素まで親要素を辿る処理が発生します。しかも、これはセレクターのどこまでマッチしたかに関係ありません。なぜなら、子孫結合子の左の単純セレクターにマッチする要素が存在しないことを確かめるには、祖先要素を全て確認しないといけないためです。また、最悪の状況での判定処理をこれ以上少なくすることはできません*6。
さて、マッチする1個の要素(γ)では、最善の場合は
- spanにマッチするか…マッチしたので親要素を辿る
- 1個上の要素はaにマッチするか…マッチしたので親要素を辿る
- 2個上の要素はliにマッチするか…マッチしたので親要素を辿る
- 3個上の要素はulにマッチするか…マッチしたので親要素を辿る
の4回ですが、場合によっては次のようになってしまうかもしれません。
- spanにマッチするか…マッチしたので親要素を辿る
- …
- n個上の要素はaにマッチするか…マッチしたので親要素を辿る(liを探す)
- …
- m個上の要素はliにマッチするか…マッチたので親要素を辿る(ulを探す)
- …
- o個上の要素はulにマッチするか…マッチしたので終了
ただ、これも判定処理が10回を超えることはありません。
繰り返しになりますが、子孫結合子を1つでも使うと、ルート要素まで親要素を辿る処理が発生しえます。これは変えようがありません。ですが、この最悪のケースの発生頻度を減らすことはできます。これも次のようなアプローチが考えられます。
子孫結合子の右に、マッチ頻度が低い単純セレクターを記述
子孫結合子よりも右に、マッチする要素がページに出現する頻度が低いセレクターを記述すると、マッチしない要素の判定回数を減らすことができます。次のような例を考えてみましょう。
ul li a span { } /* A */
ul li a span#foo { } /* B */
そして、これも同様にspan要素が100個あったとしましょう。
- 祖先にa要素が存在しないものが50個(α)
- 祖先にa要素が存在するものが50個
- a要素の祖先にli要素が存在しないものが49個(β)
- ul li a span#foo にマッチするのものが1個(γ)
また、span要素の祖先要素の数はすべて9とします。
すると、Aでは、99個(αとβ)の要素で10回判定(ルート要素まで判定)、1個の要素(γ)で4~10回判定しますが、Bのセレクターでは、99個の要素(αとβ)で1回判定して終わり、1個の要素(γ)で4~10回判定して終わります。

というのも、99個の要素では
- span#fooにマッチするか…マッチしないので終了
となるからです。
ただし、次のように、出現頻度が低いセレクターの右に子孫結合子があると、意味がありません。
ul li a#foo span { } /* C */
同様の例を考えてみます。
- 祖先にa要素が存在しないものが50個(α)
- 祖先にa要素が存在するものが50個
- a要素にid属性がないものが49個(β)
- ul li a#foo span にマッチするのものが1個(γ)
99個の要素(αとγ)で10回判定が行われます。
- spanにマッチするか…マッチしたので親要素を辿る
- 1つ上の要素はa#fooにマッチするか…マッチしないので親要素を辿る(a#fooを探す)
- …
- 9つ上の要素(ルート要素)はa#fooにマッチするか…マッチしないので親要素を辿ろうとしても親要素はないので終了
あくまでも「子孫結合子の中で最も右にあるもの」の右に出現頻度が低いセレクターを記述します。
子孫結合子よりも左に、ページ内でマッチ頻度が高い単純セレクターを記述
子孫結合子よりも左に、マッチする要素がページに出現する頻度が高いセレクターを記述することで、先祖のマッチングを素早く終わらせることができます。子孫結合子を使った場合にマッチングを素早く終えるようにする、ということは、セレクターにマッチする要素をできる限り増やすという意味です。
次のような例を考えてみます。
ul li a span { } /* A */
* * * span { } /* B */
また同様のspan要素を考えると、Aのセレクターでは、99個の要素で10回判定、1個の要素で4~10回判定します。しかし、Bのセレクターでは、99個の要素で4回判定、1個の要素で4~10回判定します。

99個の要素(αとβ)では
- spanにマッチするか…マッチしたので親を辿る
- *にマッチするか…マッチしたので親を辿る
- *にマッチするか…マッチしたので親を辿る
- *にマッチするか…マッチしたので終了
となるためです。
現実には「* * * span」とは書けないでしょうが、子孫結合子を使っている場合はマッチする要素をできる限り増やすことで、判定回数を減らすことができます。
③1回1回のマッチするかどうかの判定を速くする
判定回数を変えられない場合には、1回1回の判定処理を早くすることが考えられます。ただ、私にはこれに関してほとんど知見がありません。Constellationさんの話を聞いた限りでは、WebKitでは
とのことです。ということは、.classよりも#idやelementの方が比較処理の回数が平均して少ないでしょう。また、div#idより#idの方が比較回数が減るでしょう。比較回数が少なければそれだけ処理も速いだろうと考えています。
まとめ
この記事の内容よりも、ブラウザーが賢くなれば、これまで見てきたアプローチは役に立たなくなります。また、セレクターマッチングはCSSに関する処理の一部なので、セレクターマッチングのコストを下げても、ほかにしわよせが来る可能性があります。ただ、2012年の記事ですが、ESウェブブラウザ通信によるとセレクター マッチングがCSSの処理の中で一番重い処理
ということです。
また、セレクターマッチングのコストが低いセレクターと、理解しやすい・メンテナンスしやすいセレクターは別です。パフォーマンスが良くてもメンテナンスできなくては意味がありません。メンテナンスできるセレクターを心がけましょう。