CSSセレクターマッチングのコスト
ブラウザエンジン先端観測会での、Constellationさんの話を聴いて、CSSセレクターマッチングのコストには複数のレベルがあることを強く意識するようになりました。セレクターマッチングにかかるコストを下げたい、という場合には、どのレベルで何を高速化しようとしているのかを意識しないと話がかみあいません。Constellationさんの話を私なりに整理して考えた、セレクターマッチングのコストを下げるアプローチは次の3つです。
- ①セレクターを減らす
- ②マッチするかどうかの判定回数を減らす
- ③1回1回の判定処理を速くする
これは、ブラウザーのセレクターマッチングの処理の各部分に対応しています。
この記事の残りでは、Constellationさんの話を私なりに整理した結果を書きます。ですので、ブラウザエンジン先端観測会でのConstellationさんの話以上の知見はありません。
- CSS JIT: Optimizing CSS Selector Matching with Just-in-Time Compilation
- ブラウザエンジン先端観測会 アウトラインメモ
- ブラウザエンジン先端観測会 #1
①セレクターを減らす
ブラウザーはCSSに記述されている各セレクター*1について、対象となる要素すべてにマッチするかどうかの判定を行います。多くの場合、「対象の要素すべて」はページ内の全要素になります。
また、WebKitは、「セレクターの中に#idがあるのでまず#idの子孫を絞り込んでからマッチする要素を探す」といった処理を行わないとのことです。愚直にすべての要素を対象にマッチするかどうかの判定を行うとのことです。Constellationさんによるとdocument.querySelector の実装である SelectorQuery.cpp の方で事前に filtering を行うことによって, この #id が含まれるケースの絞り込みが行われています
とのことです。詳しくはコメントを参照してください。
さらに、Constellationさんによると、WebKitは、セレクターが矛盾していない限り*2、すべてのセレクターについてマッチング処理を行うとのことです。
以上を踏まえると、WebKitはセレクターが100個記述されていると100回処理します。これも単純に100回処理するのではなく、(100×ページ内の全要素数)回処理をします。しかも、後で見るように、1つの要素がセレクターにマッチするかどうかの判定が1回で終わるとは限りません。仮にページ内に要素が100個あり、判定処理を平均10回行うとすると、100セレクターでは100×100×10=100000回(10万回)の処理が発生します。一方、同じ条件でセレクターを1つにできれば、1×100×10=1000回の処理で済みます。これが①セレクターを減らす、の意味です。
②マッチするかどうかの判定回数を減らす
セレクターの数を変えられない場合には、ある要素がセレクターにマッチするかどうかの判定回数を下げるというアプローチがあります。ブラウザーは
- セレクターそれぞれについて(①)、
という処理をしているので、②の処理が小さくなるようにセレクターを調整します。そのためにはブラウザーの処理を考える必要があります。ブラウザー先端観測会ではこの部分が丁寧に解説されました。
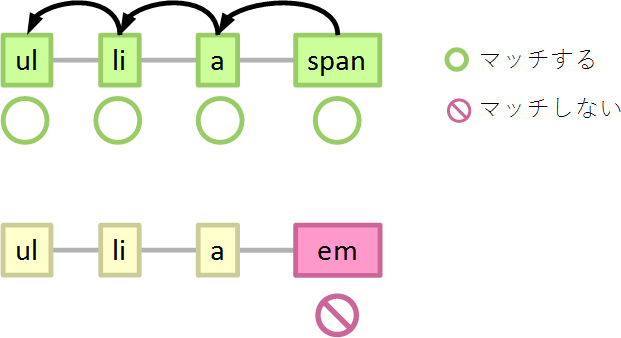
ブラウザーはある要素がセレクターにマッチするかしないかを、セレクターの右から評価していきます。
ul > li > a > span { }
と書いてあれば、ページの中の要素の1つ1つに対して、
- spanにマッチするか…マッチしたら親要素を辿る、しなければ終了
- aにマッチするか…マッチしたら親要素を辿る、しなければ終了
- liにマッチするか…マッチしたら親要素を辿る、しなければ終了
- ulにマッチするか…マッチしたら終了、しなくても終了
という順番に判定していきます。となると、マッチするかどうかの判定が4回かかるセレクターよりも、1回で済むセレクターの方が、マッチングのコストが小さそうです(早く処理を終えることが期待できます)。
span { }
- spanにマッチするか…マッチしたら終了、しなければ終了
また、ここで考えておきたいのは、セレクターが要素にマッチするときの処理だけが早くなっても効果は薄いだろうということです。というのも、あるセレクターにマッチする要素はページの中で少数派であることがほとんどだからです。しかし、セレクターマッチングはすべての要素に対して行われるので、マッチしない要素の方が多数派という状況が多く発生します。であるならば、少数派の処理時間だけではなく、多数派と少数派の両方の処理時間を考えた方が良いでしょう。例えば、ユーザーが選択中のタブにスタイルをあてるために、次のようなセレクターを書くとしましょう。
.tablist > li > a.selected { }
ページの中に選択中のタブが1個しかなければ、マッチするのは1回だけで、ほかの要素はマッチしません。ということは、処理時間の大半はマッチしない要素に費やされているでしょう。
以下では、マッチするかどうかの判定回数を減らすアプローチを考えていきます。Constellationさんの話では、親要素*3を辿って判定する回数は結合子(「 」「>」「+」「~」など)によって異なるということでした。そこで、以下では結合子ごとに考えます。
結合子なし(単純セレクターのみ)
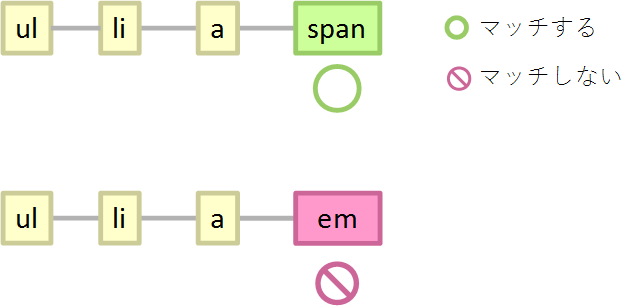
結合子なし(単純セレクターのみ*4)の場合、どんなに悪い状況でも、1つの要素につき1回しか判定しません。
span {}
対象となる要素すべて(ページ内のすべての要素)に対して1回だけマッチするかどうかの判定を行って、それでおしまいです。また、判定処理は0回にできないので、判定1回は最善の状況です。
子供結合子(E > F)しかない場合
子供結合子しか使わない場合は、どんなに悪い状況でも、1つの要素につき(子供結合子の数+1)回しか判定しません。
次の例を考えてみましょう
ul > li > a > span {}
この例は、一番悪い状況は対象要素がセレクターにマッチする場合で、4回判定します。
- spanにマッチするか…マッチしたので親要素を辿る
- aにマッチするか…マッチしたので親要素を辿る
- liにマッチするか…マッチしたので親要素を辿る
- ulにマッチするか…マッチしたので終了
逆に、一番良い状況は、セレクターの一番右が対象要素にマッチしない場合です。
- spanにマッチするか…マッチしなかったので終了
これは1回しか判定を行わないので、結合子なしと同じ最善の状況です。まあまあな状況では、セレクターの一部にマッチする要素について、2回もしくは3回マッチするかどうかの処理を行います。
以上を踏まえると、子供結合子しか使わない場合に、親要素を辿る処理を減らすには、次のようなアプローチが考えられます。
- 子供結合子の数を減らす
- 子供結合子の右に、マッチ頻度が低い単純セレクターを記述
子供結合子の数を減らす
子供結合子しか使わない場合、どんな状況でも(子供結合子の数+1)回より多く判定を行うことはないわけですから、結合子の数が減ればそれだけで状況は改善します。
ul > li > a > span {} /* A */
ul > li > a { } /* B */
Aでは、最悪(マッチ)は4回判定、まあまあ(部分的にマッチ)が2~3回判定、最善(完全にマッチしない)が1回判定ですが、Bでは、最悪(マッチ)は3回判定、まあまあ(部分的にマッチ)が2回判定、最善(完全にマッチしない)が1回判定になりました。
子供結合子の右に、マッチ頻度が低い単純セレクターを記述
子供結合子の右に、マッチする要素がページに出現する頻度が低いセレクターを記述するアプローチは、親要素を辿りにいく要素を減らすことを意図しています。このアプローチでは最悪の場合は改善できませんが、それ以外の状況は改善できるでしょう。
例えば、次のようなセレクターを考えてみましょう。
ul > li > a > span { } /* A */
ul > li > a > span#foo { } /* B */
ページの中に、span要素が100個あったとしましょう。そのうち
- 親がa要素でないものが50個(α)
- 親がa要素であるものが50個
- 親がli要素でないものが49個(β)
- ul > li > a > span#foo にマッチするのものが1個(γ)
すると、Aでは、50個の要素(α)で2回判定、49個の要素(β)で3回判定、1個の要素(γ)で4回判定します。
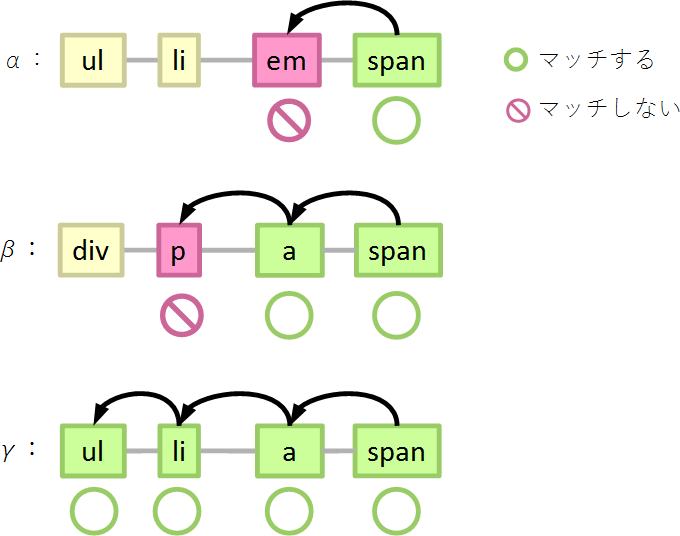
詳しく見ると、50個の要素(α:親がaでない)では、
- spanにマッチするか…マッチしたので親を辿る
- aにマッチするか…マッチしないので終了
49個の要素(β:親がaだが、aの親はliでない)では、
- spanにマッチするか…マッチしたので親を辿る
- aにマッチするか…マッチしたので親を辿る
- liにマッチするか…マッチしないので終了
1個の要素(γ)では、
- spanにマッチするか…マッチしたので親を辿る
- aにマッチするか…マッチしたので親を辿る
- liにマッチするか…マッチしたので親を辿る
- ulにマッチするか…マッチしたので終了
となります。
しかしBのセレクターでは、99個の要素(αとβ)で1回判定して終わり、1個の要素(γ)で4回判定して終わり、になります。
ul > li > a > span#foo { } /* B */
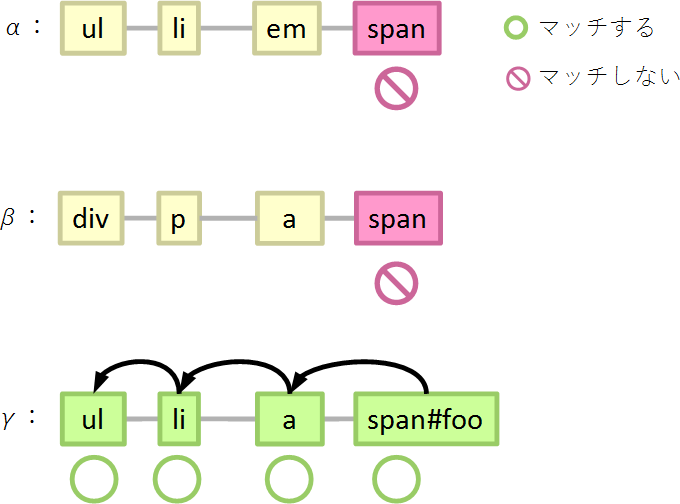
詳しく見ると、99個の要素(αとβ:spanがspan#fooでない)では、
- span#fooにマッチするか…マッチしないので終了
となります。
ブラウザーはセレクターを右から順番に評価する、ということは、左に進ませなければ、それだけ処理を早く終わらせることができます。左に進ませないようにするには、右側に出現頻度の低いセレクターを記述することです。
子供結合子しか使っていない場合は、出現頻度の低い単純セレクターをどの子供結合子の右に書いても、一定の効果が期待できます。次のような例を考えてみましょう。
ul > li > a > span { } /* A */
ul > li > a#foo > span { } /* C */
ここでもページの中に、span要素が100個あったとしましょう。そのうち
- 親がa要素でないものが50個(α)
- 親がa要素であるものが50個
- a要素にid属性が指定されていないものが49個(β)
- ul > li > a#foo > span にマッチするのものが1個(γ)
とします。
Aでは、50個の要素(α)で2回判定、49個の要素(β)で3回判定、1個の要素(γ)で4回判定します。しかし、Cでは、99個の要素(αとβ)で2回判定して終わり、1個の要素(γ)で4回判定して終わり、になります。
99個の要素(αとβ:親がa#fooでない)では
- spanにマッチするか…マッチしたので親を辿る
- a#fooにマッチするか…マッチしないので終了
となるためです。
さすがにここまで極端な記述はできないと思いますが、子孫結合子だけを使う場合、セレクターの右側にマッチしにくいものを記述することで、親要素を辿って判定する処理を減らすことができます。
子孫結合子(E F)を使う場合
子孫結合子を使う場合は、やや複雑です。これも次の例を使って考えてみましょう。
ul li a span {}
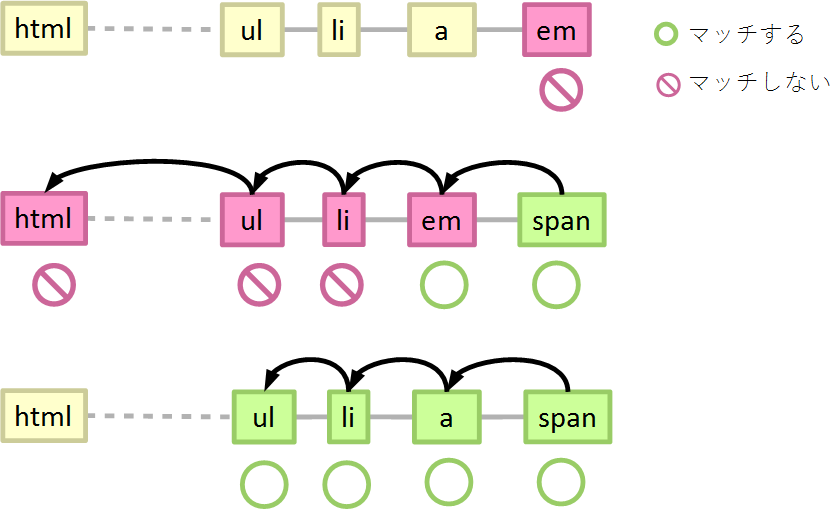
まず、最善の場合です。子孫結合子を使う場合の最善の場合は、一番右の子孫結合子の右に記述されているセレクター(span)に要素がマッチしない場合です。
- spanにマッチするか…マッチしないので終了
子孫結合子の右にマッチしなければ、そこで処理は終了するので、1回*5しか判定しません。
最悪の場合は、セレクターの一部がマッチするが、全体としてはマッチしない要素です。この例の場合には、a要素に含まれないspan要素などが該当します。a要素に含まれないspan要素を考えると、
- spanにマッチするか…マッチしたので親要素を辿る
- aにマッチするか…マッチしないので親要素を辿る
- (ルート要素まで親要素を辿って判定する処理を繰り返し)
- ルート要素はaにマッチするか…マッチしないので親要素を辿る…ルート要素には親要素がないので終了
子孫結合子の左にマッチする要素が存在しないことを確かめるには、祖先を全て確認しないといけないため、親要素を辿る処理が増えます。存在する場合には、親要素を辿っている途中で見つかるので、全て確認しなくても処理は終わります(まあまあの場合)。
ここでも例を考えてみましょう。
ul li a span {}
やはりページの中に、span要素が100個あったとしましょう。そのうち
- 祖先にa要素が存在しないものが50個(α)
- 祖先にa要素が存在するものが50個
- a要素の祖先にli要素が存在しないものが49個(β)
- ul li a span にマッチするのものが1個(γ)
また、話を簡単にするためにspan要素の祖先要素の数はすべて9としましょう。この場合、99個の要素(αとβ)で10回判定、1個の要素(γ)で4~10回判定します。
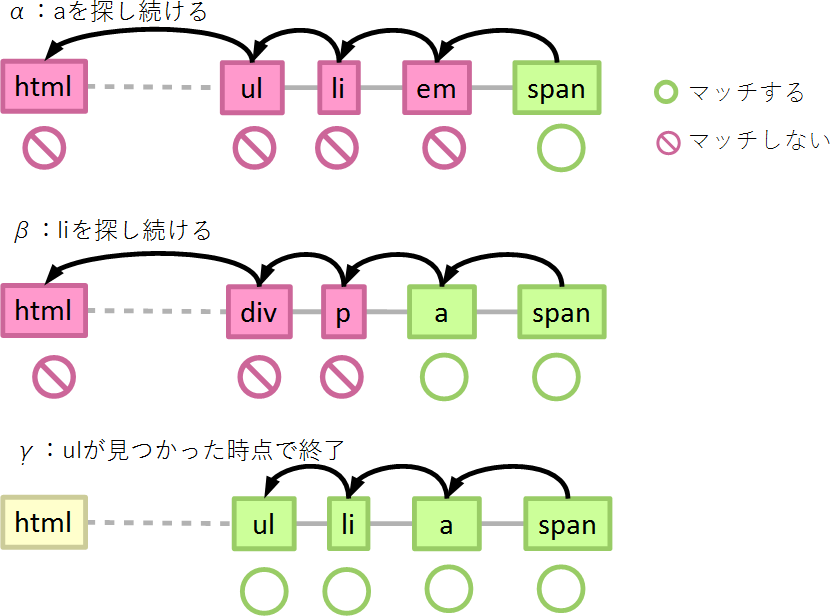
詳しく見てみると、50個の要素(α:祖先にaが存在しない)では
- spanにマッチするか…マッチしたので親要素を辿る
- 1個上の要素はaにマッチするか…マッチしないので親要素を辿る(aを探す)
- …
- 9個上の要素(ルート要素)はaにマッチするか…マッチしないので親要素を辿ろうとしても親要素はないので終了
の10回判定を行います。
49個の要素(β:祖先にliが存在しない)でも
- spanにマッチするか…マッチしたので親要素を辿る(aを探す)
- …
- n個上の要素はaにマッチするか…マッチしたので親要素を辿る(liを探す)
- …
- m個上の要素はliにマッチするか…マッチしないので親要素を辿る(liを探す)
- …
- 9個上の要素(ルート要素)はliにマッチするか…マッチしないので親要素を辿ろうとしても親要素はないので終了
の10回判定処理を行います。
このように、子孫結合子を使った場合、セレクターの一部にマッチして全体がマッチしない要素では、ルート要素まで親要素を辿る処理が発生します。しかも、これはセレクターのどこまでマッチしたかに関係ありません。なぜなら、子孫結合子の左の単純セレクターにマッチする要素が存在しないことを確かめるには、祖先要素を全て確認しないといけないためです。また、最悪の状況での判定処理をこれ以上少なくすることはできません*6。
さて、マッチする1個の要素(γ)では、最善の場合は
- spanにマッチするか…マッチしたので親要素を辿る
- 1個上の要素はaにマッチするか…マッチしたので親要素を辿る
- 2個上の要素はliにマッチするか…マッチしたので親要素を辿る
- 3個上の要素はulにマッチするか…マッチしたので親要素を辿る
の4回ですが、場合によっては次のようになってしまうかもしれません。
- spanにマッチするか…マッチしたので親要素を辿る
- …
- n個上の要素はaにマッチするか…マッチしたので親要素を辿る(liを探す)
- …
- m個上の要素はliにマッチするか…マッチたので親要素を辿る(ulを探す)
- …
- o個上の要素はulにマッチするか…マッチしたので終了
ただ、これも判定処理が10回を超えることはありません。
繰り返しになりますが、子孫結合子を1つでも使うと、ルート要素まで親要素を辿る処理が発生しえます。これは変えようがありません。ですが、この最悪のケースの発生頻度を減らすことはできます。これも次のようなアプローチが考えられます。
子孫結合子の右に、マッチ頻度が低い単純セレクターを記述
子孫結合子よりも右に、マッチする要素がページに出現する頻度が低いセレクターを記述すると、マッチしない要素の判定回数を減らすことができます。次のような例を考えてみましょう。
ul li a span { } /* A */
ul li a span#foo { } /* B */
そして、これも同様にspan要素が100個あったとしましょう。
- 祖先にa要素が存在しないものが50個(α)
- 祖先にa要素が存在するものが50個
- a要素の祖先にli要素が存在しないものが49個(β)
- ul li a span#foo にマッチするのものが1個(γ)
また、span要素の祖先要素の数はすべて9とします。
すると、Aでは、99個(αとβ)の要素で10回判定(ルート要素まで判定)、1個の要素(γ)で4~10回判定しますが、Bのセレクターでは、99個の要素(αとβ)で1回判定して終わり、1個の要素(γ)で4~10回判定して終わります。

というのも、99個の要素では
- span#fooにマッチするか…マッチしないので終了
となるからです。
ただし、次のように、出現頻度が低いセレクターの右に子孫結合子があると、意味がありません。
ul li a#foo span { } /* C */
同様の例を考えてみます。
- 祖先にa要素が存在しないものが50個(α)
- 祖先にa要素が存在するものが50個
- a要素にid属性がないものが49個(β)
- ul li a#foo span にマッチするのものが1個(γ)
99個の要素(αとγ)で10回判定が行われます。
- spanにマッチするか…マッチしたので親要素を辿る
- 1つ上の要素はa#fooにマッチするか…マッチしないので親要素を辿る(a#fooを探す)
- …
- 9つ上の要素(ルート要素)はa#fooにマッチするか…マッチしないので親要素を辿ろうとしても親要素はないので終了
あくまでも「子孫結合子の中で最も右にあるもの」の右に出現頻度が低いセレクターを記述します。
子孫結合子よりも左に、ページ内でマッチ頻度が高い単純セレクターを記述
子孫結合子よりも左に、マッチする要素がページに出現する頻度が高いセレクターを記述することで、先祖のマッチングを素早く終わらせることができます。子孫結合子を使った場合にマッチングを素早く終えるようにする、ということは、セレクターにマッチする要素をできる限り増やすという意味です。
次のような例を考えてみます。
ul li a span { } /* A */
* * * span { } /* B */
また同様のspan要素を考えると、Aのセレクターでは、99個の要素で10回判定、1個の要素で4~10回判定します。しかし、Bのセレクターでは、99個の要素で4回判定、1個の要素で4~10回判定します。

99個の要素(αとβ)では
- spanにマッチするか…マッチしたので親を辿る
- *にマッチするか…マッチしたので親を辿る
- *にマッチするか…マッチしたので親を辿る
- *にマッチするか…マッチしたので終了
となるためです。
現実には「* * * span」とは書けないでしょうが、子孫結合子を使っている場合はマッチする要素をできる限り増やすことで、判定回数を減らすことができます。
③1回1回のマッチするかどうかの判定を速くする
判定回数を変えられない場合には、1回1回の判定処理を早くすることが考えられます。ただ、私にはこれに関してほとんど知見がありません。Constellationさんの話を聞いた限りでは、WebKitでは
とのことです。ということは、.classよりも#idやelementの方が比較処理の回数が平均して少ないでしょう。また、div#idより#idの方が比較回数が減るでしょう。比較回数が少なければそれだけ処理も速いだろうと考えています。
まとめ
この記事の内容よりも、ブラウザーが賢くなれば、これまで見てきたアプローチは役に立たなくなります。また、セレクターマッチングはCSSに関する処理の一部なので、セレクターマッチングのコストを下げても、ほかにしわよせが来る可能性があります。ただ、2012年の記事ですが、ESウェブブラウザ通信によるとセレクター マッチングがCSSの処理の中で一番重い処理
ということです。
また、セレクターマッチングのコストが低いセレクターと、理解しやすい・メンテナンスしやすいセレクターは別です。パフォーマンスが良くてもメンテナンスできなくては意味がありません。メンテナンスできるセレクターを心がけましょう。
PUAアイコンフォントのアクセシビリティ
UnicodeのPUA(Private Use Area:私用領域)を使ったアイコンフォント(FontAwesomeなど)には、いくつかアクセシビリティ上の問題があります。この記事では、問題点、対処療法的な解決方法、本質的な解決方法(となりうるもの)について簡単にみていきます。
UnicodeのPUAは私用領域、私的な利用のために使って良い文字(コードポイント)のための領域です。私用領域でない定義された文字(コードポイント)はどの環境でも一意に解釈されるのに対して、PUAの文字(コードポイント)は人/フォント/システムによって解釈が異なります。例えば、PUAでない「U+3042」はどの環境でも「ひらがなのあ」に対応しているものとして解釈されますが、PUAの範囲内はそうではありません。
PUAアイコンフォントの問題
PUAアイコンフォントには、いくつかアクセシビリティ上の問題があります。
- 1 スクリーン・リーダーなどにPUAを無視させるのが難しい
- 2 (代替テキストが設定されていない場合)スクリーン・リーダーなどが情報を読み上げられない
- 3 アイコンフォントが使われない環境で、視覚的に情報が伝わらない
1はCSSの擬似要素で追加されたPUAをスクリーン・リーダーが読み上げる、というものです。この問題の解決のためにaria-hidden="true"を使う方法が提案されていますが、その場合でもスクリーン・リーダーがPUAを読み上げる場合があります*1。
2の解決は簡単です。いわゆるスクリーン・リーダー対策と呼ばれるテクニックを使えば、スクリーン・リーダーにだけ特定の情報を読み上げさせることができます。例えば、HTMLに代替テキストを書いて視覚的に隠すとか、title属性を指定するとか、aria-label属性を指定するとか、といった方法があるでしょう。
3.は、いくつかの環境ではPUAがアイコンのグリフで表示されないため、情報を取得できないという問題です。例えば次のような環境です。
- Webフォントをサポートしていない/無効にした場合
- アイコンフォントのダウンロードに失敗したした場合
- ユーザー指定のフォントが優先して使われる場合
ユーザー指定のフォントが優先される場合には、アイコンはアイコンとして表示されません。このため、特にアイコンだけで情報を伝えている場合(隣りにテキストがない場合、など)、ページが何を伝えようとしているのかわりません。
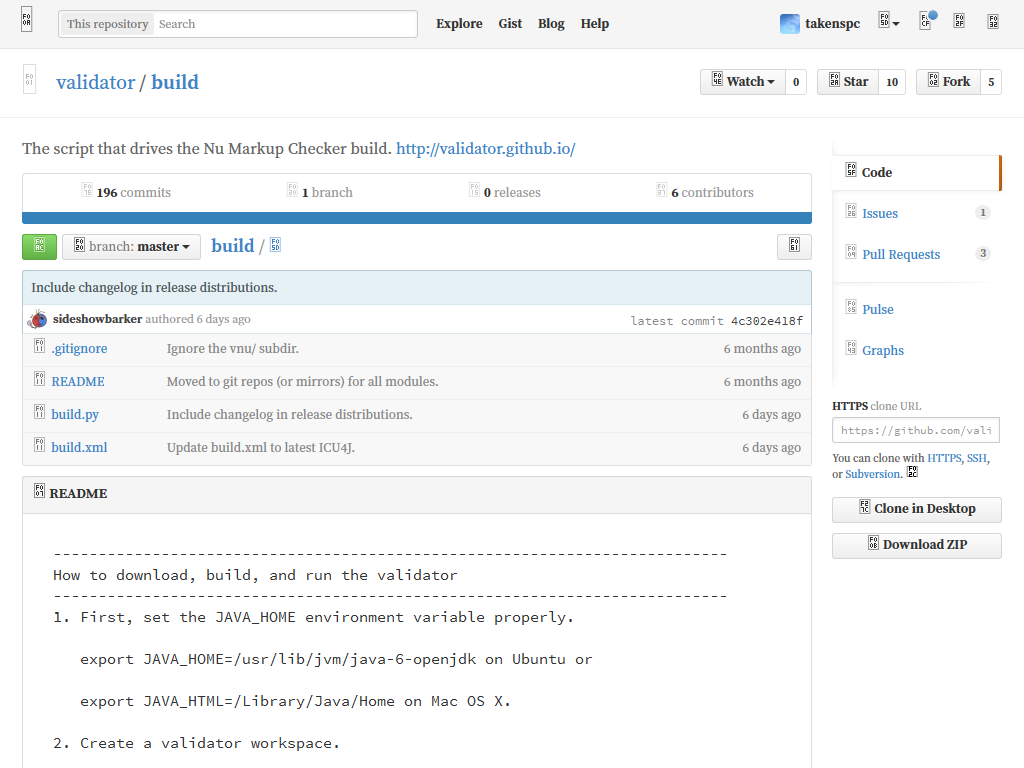
例えば、GitHubはアイコンフォントを多用しており、かつアイコンしか設定されていないボタンも多くあるため、マウスを重ねてツールチップが出てこないと何をするボタンなのかわかりません。
また、PUAはフォントあるいはシステムによってどんな表示をされるのか、予想ができません。ユーザーが使っているフォントにグリフがない場合、多くのブラウザーは四角や四角の中にコードポイントが表示された形で表示しますが、ユーザーが使っているフォントにグリフがある場合には、制作者が想定していたのとは異なる意味をもつグリフが表示される場合があります。Bulletproof Accessible Icon Fontsには、そのような残念な表示になった例がいくつか出ています。四角の中に宇宙人のような顔が表示されていたり、ハングルが表示されていたりと、フォントによって、制作者の意図とかけはなれた情報が伝わってしまいます。
脱線しますが、「ユニコード戦記」には「香港政府がカントニーズに特有の人名用漢字をPUAに割り当てて、行政用に使い始め」、「お馬鹿なことに、得々としてこれを国際ユニコード会議の場で発表する輩」がいたという話がでてきますが、PUAアイコンフォントがやっていることはそれと同じです。
PUAは、たとえそれがある国や地域に限定されるものであったとしても、セミパブリックな用途には絶対に使うべきではない。私用領域はシステム内部での臨時の使い捨ての領域であって、外部から見える符号位置としては限りなく使用禁止に近いものと考えるべきである。
と同書には書かれています。
いずれにせよ、「スクリーン・リーダー対応だけをすればコンテンツがアクセシブルになる」というわけではないため、制作者は3も考えなくてはなりません。そして、3の解決は1や2に比べると難しいです。
Adobe Blankを使う方法
The Paciello GroupがCSUN 2014で行った発表では、PUAアイコンフォントを使ったうえで、
- 代替となるテキストをHTMLに記述する
- 代替となるテキストはAdobe Blankを使って視覚的に見えなくする
という方法が紹介されていました。Adobe Blankはすべての文字が視覚的には見えないフォントです。
- Lessons Learned: Accessibility Theory vs. Implementation Reality セッション情報
- Lessons Learned: Accessibility Theory vs. Implementation Reality スライドと例
- Adobe Blank
この方法を使うと、3.の視覚的な問題も部分的に解決可能です。というのも、ユーザーのフォント設定が優先されている場合には、
- アイコンフォントが指定されている部分はそのまま表示される
- Adobe Blankが指定されている部分もそのまま表示される
ため、代替となるテキストが画面上に表示されるからです。
ただし、Paciello Groupが発表した方法をそのまま使うと、次のような問題が起こります。
- Adobe Blankが読み込まれた/使われているが、アイコンフォントが読み込まれていない/使われていない場合に、代替となるテキストが視覚的に見えない
この場合、画面上にはPUAだけが表示され、代替テキストは表示されません。アイコンフォントが読み込まれ、かつ、使われていることを確認する方法があれば、アイコンフォントが使われていることを確認できた段階で代替テキストにAdobe Blankを適用することで、この問題は解決できるでしょう。
リガチャーアイコンフォント
とはいえ、こんなに頑張らないとアクセシブルにできない技術を使うのは、そもそもどうなのでしょう。シンボルフォント — それは、新しい画像形式では「PUAを使う方法」はヒトの進化における類人猿(?)に例えられています(時間軸では類人猿(?)が現在ということになっていますが…)。
アイコンフォントにはPUAを使わないものもあります。例えば、Ligature Symbolsは、リガチャー(合字)を使ったアイコンフォントです。
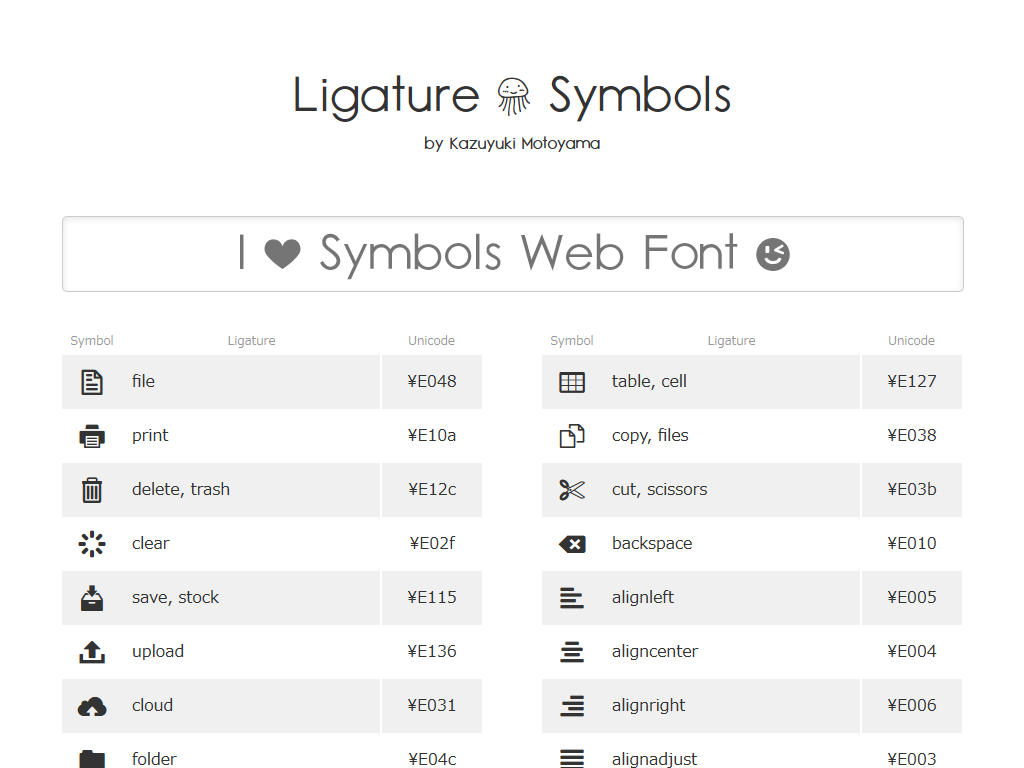
このフォントでは「print」や「upload」といった単語に対してアイコンが指定されています。保存用のアイコンを表示する部分には、次のようなHTMLが記述されています。
<td class="lsf symbol">save</td>
Ligature Symbolsでは、代替テキストを別途用意する必要はありませんし、フォントの読み込みに失敗したり、ユーザーのフォント指定が優先される場合のことを特別に考える必要はありません。HTMLにテキストが書かれているので、フォントが読み込まれない/使われない場合には単にテキストが表示されるからです。

リガチャーを使ったフォントはSVGフォントであれば手で作成・調整できます(glyph要素のunicode属性を弄れば良い)。が、SVGフォントはSVG 2では廃止されるので、別の方法を使って効率的に作成・調整する方法を考えるべきでしょう。Ligature Symbolsであればカスタマイズ方法も紹介されていますが、私もフォントの作成方法に明るくないので、フォントもくもく会でもう少し考えを深めてみたいないと思っています。
vnu.jarでコマンドラインからNu Markup Checkerを使う
Nu Markup Checkerにはコマンドラインから呼び出して使えるバージョンもあります(validator.github.io)。この記事では一応、vnu.jarと呼ぶことにします。vnu.jarを使うとローカルに置いたHTML5のチェックは次のように関単に行うことができます。
$ java -jar vnu.jar html/index.html
"file:/path/to/html/index.html":8.46-8.46: error: End tag “h5” seen, but there were open elements.
"file:/path/to/html/index.html":8.50-8.50: error: No “p” element in scope but a “p” end tag seen.
vnu.jarを使うと単一のHTMLファイルだけではなく、フォルダ単位で一度にチェックすることも可能です。
$ java -jar vnu.jar html
"file:/path/to/html/index.html":8.46-8.46: error: End tag “h5” seen, but there were open elements.
"file:/path/to/html/index.html":8.50-8.50: error: No “p” element in scope but a “p” end tag seen.
"file:/path/to/html/sub_dir/index.html":8.24-8.24: error: End tag “p” seen, but there were open elements.
"file:/path/to/html/sub_dir/index.html":8.15-8.15: error: Unclosed element “a”.
"file:/path/to/html/sub_dir/index.html":9.7-9.7: error: End tag for “body” seen, but there were unclosed elements.
validator.github.ioによるとvnu.jarを使ったHTMLの検証を行うgruntのプラグインもあるそうです(grunt-html)。
便利なvnu.jarですが、検証内容には注意が必要です。
この記事を書いている段階で最新の2014年8月25日版vnu.jarはW3Cの仕様(HTML 5.1など)ではなくHTML Living Standardに沿っているかをチェックします。そのためhttp://validator.w3.org/とのチェック結果とは一致しない部分がいくつかあります。例えば、vnu.jarはhgroup要素に対してエラーを報告しませんが、http://validator.w3.org/はエラーを報告します。W3Cの仕様に沿うかどうかはNu Markup Checkerのビルド時にRelaxスキーマを書き換えることで行っている(build.py)ため、jarファイルを弄らずに変更することはできません(vnu.jarの中にRelaxスキーマが格納されています)。
また、Nu Markup Checkerは現在も開発が続いている(githubのプロジェクト)ため、自分が使っているvnu.jarと最新のNu Markup Checkerのチェック結果が異なる可能性がある点にも注意が必要です。
Nu Markup CheckerでもHTML 4とXHTML 1.0のチェック
先日、Nu Markup Checker(http://validator.nu/)でHTMLファイルをチェックするBrackets用の拡張機能を作りました(Nu Markup Checker for Brackets)。拡張機能自体はありきたりで、特に何というほどのものでもないのですが、この記事ではNu Markup Checker単独でHTML 4やXHTML 1.0のチェックを行う方法について述べたいと思います。
Nu Markup Checkerは主にHTML5のチェックに使われていますが、HTML 4とXHTML 1.0のチェックを行うこともできます。その際、HTML 4とXHTML 1.0に対しても単なるDTDのチェック(に相当するチェック*1)だけではなく、表の列数が行によって異なっていないかどうかやusemap属性値が妥当かどうかなどのチェックも行うことができます。ただし、そのためにはパラメーターをいくつか設定する必要があります。
tl;dr
(この記事執筆時点で)Nu Markup Checker単独でHTML 4とXHTML 1.0をチェックするためのパラメーターの組み合わせは次の通りです。
| 文書型 | sniffdoctype | parser | preset |
|---|---|---|---|
| HTML 4.01 Strict | yes | 指定しない | 指定しない |
| HTML 4.01 Transitional | yes | 指定しない | 指定しない |
| XHTML 1.0 Strict | 指定しない | xmldtd | http://s.validator.nu/xhtml10/xhtml-strict.rnc http://s.validator.nu/html4/assertions.sch http://c.validator.nu/all-html4/ |
| XHTML 1.0 Transitional | 指定しない | xmldtd | http://s.validator.nu/xhtml10/xhtml-transitional.rnc http://s.validator.nu/html4/assertions.sch http://c.validator.nu/all-html4/ |
DOCTYPE(sniffdoctype)
Nu Markup CheckerはRelaxNG、Schematron、Javaで書かれたチェッカーを組み合わせてファイルをチェックします(syntax)。この組み合わせは変更可能で、Nu Markup Checkerには最初からいくつかのプリセットが用意されています。デフォルトではHTML5用のプリセットでファイルをチェックします。ですが、Nu Markup Checkerには文書のDOCTYPEを見てチェック用プリセットを変更する機能があります。
Nu Markup Checkerへ渡すクエリにsniffdoctype=yesを付与すると、DOCTYPEがXHTML 1.0、HTML 4.01、HTML 4.0のTransitionalとStrictの場合、適切なプリセットが設定されます。sniffdoctypeなしではHTML5としてチェックされるHTML 4、XHTML 1.0も、sniffdoctype=yesを付けるとHTML 4やXHTML 1.0としてチェックされるようになります。例えば、HTML4やXHTML 1.0でa要素の中にブロック要素を記述していても、通常はスルーされますが、sniffdoctype=yesを付けるとエラーが報告されます。
ただし、この方法にもいくつかの欠点があります。
HTML5をチェックしようとするとシステムエラーが発生する件は、DOCTYPEをみてパラメーターの付与を調整することで外から対応できますが、XHTMLをHTMLパーサーで処理する件はNu Markup Checkerで使われているパーサーの話なのでsniffdoctypeパラメーターでは設定できません。実際にsniffdoctype=yesを付けてXHTML 1.0 Strictをチェックしようとすると、次のような注意が表示されます。
Info: XHTML 1.0 Strict doctype seen. Appendix C is not supported. Proceeding anyway for your convenience. The parser is still an HTML parser, so namespace processing is not performed and xml:* attributes are not supported. Using the schema for HTML 4.01 or XHTML 1.0, Strict.
XHTMLがHTMLパーサーで処理されると次のような問題が起こります(Appendix CはXHTML 1.0のAppendix C)。
- 名前空間をサポートしていないため、xml:lang属性などを認識できない(許可されていない属性であるというエラーが報告される)
- HTMLとしてパースしているため、終了タグ忘れ(<meta>)などがエラーとして報告されない
xml:lang属性がエラーとして報告されるのは無視すれば良いのですが、報告されてほしいものが報告されないのは困ります。
パーサー(parser)とプリセット(preset)
ですが、Nu Markup Checkerはクエリにparserパラメータを指定することで、使用するパーサーを変更することができます。例えば、parser=htmlを指定するとHTML5パーサー、parser=xmldtdを指定するとXMLパーサーを使用します(通常はHTML5パーサー)。ただし、この方法で指定できるXMLパーサーにもいくつか注意すべき点があります。
XMLとしてエラーが見つかった時点で処理が終了するのはXMLパーサーとして一般的な挙動です。例えば、XMLパーサー使用時のNu Markup Checkerは、次のようなXHTML*2を渡されるとhead要素の終了タグが登場した時点で処理を終了します(meta要素の終了タグを見つける前にhead要素の終了タグが来たためです)。
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<meta http-equiv="content-type" content="text/html; charset=utf-8">
<title>Virtual Library</title>
</head>
<body>
<a href="http://example.org/"><p>Moved to example.org.</p></a>
</body>
</html>
この場合、body要素の子供としてa要素が記述されていることなどは報告されません。チェックツールとしてはいささか不親切ですが、ESLintも似たようなものなので、あきらめましょう(何)。XMLとしてwell-formedになればエラーが報告されるようになります。
もう1つのチェックのプリセットはNu Markup Checkerに含まれるテキストファイル(presets.txt)に記述されているため、同一の内容を外から指定することができます。テキストファイルは通常のプリセットとW3C(http://validator.w3.org/nu/)用のプリセットがあります。
どの文書型にどのプリセットを使うべきかはファイルを見れば想像できますが、VerifierServletTransaction.javaに定数が定義されています(「XHTML1TRANSITIONAL_SCHEMA = 1」など)。(この記事執筆時点で)プリセットの番号と文書型の対応関係は次の通りです。
| 番号 | 文書型 |
|---|---|
| 1 | HTML 4/XHTML 1.0 Transitional |
| 2 | HTML 4/XHTML 1.0 Strict |
| 3 | HTML5 |
| 7 | XHTML 5 |
これをもとにW3C版のpresets.txtを見ると、HTML 4/XHTML 1.0 Transitionalであれば1の内容
http://s.validator.nu/xhtml10/xhtml-transitional.rnc http://s.validator.nu/html4/assertions.sch http://c.validator.nu/all-html4/
を指定すれば良く、HTML 4/XHTML 1.0 Strictであれば2の内容
http://s.validator.nu/xhtml10/xhtml-strict.rnc http://s.validator.nu/html4/assertions.sch http://c.validator.nu/all-html4/
を指定すれば良いことがわかります。これとparserの指定を組み合わせれば、XHTML 1.0をXHTML 1.0としてチェックさせることができます。ParserMode.javaにモードの列挙子が、VerifierServletTransaction.javaにparserパラメータの処理が記述されています。
VerifierServletTransaction.javaを見るとXHTML 1.0にはparser=xmldtdを指定すれば良いことがわかります*3。同じく、HTML 4にはparserパラメータを指定する必要がないことがわかりますし、sniffdoctype=yesで自動的にプリセットが割り当てらることがわかります。
まとめ
このように文書型に応じてパラメーターを調整すれば、Nu Markup Checker単独でもHTML 4とXHTML 1.0もチェックを行うことができます。W3C版のプリセットを使った場合のパラメーターの組み合わせは次のようになります。
| 文書型 | sniffdoctype | parser | preset |
|---|---|---|---|
| HTML 4.01 Strict | yes | 指定しない | 指定しない |
| HTML 4.01 Transitional | yes | 指定しない | 指定しない |
| XHTML 1.0 Strict | 指定しない | xmldtd | http://s.validator.nu/xhtml10/xhtml-strict.rnc http://s.validator.nu/html4/assertions.sch http://c.validator.nu/all-html4/ |
| XHTML 1.0 Transitional | 指定しない | xmldtd | http://s.validator.nu/xhtml10/xhtml-transitional.rnc http://s.validator.nu/html4/assertions.sch http://c.validator.nu/all-html4/ |
Techniques for WCAG 2.0にコメントを送る会
先日、Techniques for WCAG 2.0にコメントを送る会をやりましたので、イベント中、およびその後で思ったこと・感じたことを書きます。
この記事ではTechniques for WCAG 2.0について思ったことの後に、個別の実装方法について思ったことの順番に書きます。また、この記事ではTechniques for WCAG 2.0(2014年7月25日付Editor's Draft)をもとに話を進めます。このEditor's Draftへのコメントは2014年8月12日*1まで募集されています(Call for Review: WCAG 2.0 Techniques Draft Updates)。
他の参加者のレポートは次の通りです。
- Techniques for WCAG 2.0にコメントを送る会にTwitterで参戦した - 血統の森+はてな
- Techniques for WCAG 2.0にコメントを送る会 | 覚え書き | @kazuhito
Techniques for WCAG 2.0について思ったこと
なんか違う
内容が間違っていることはないとまず思うのですが、議論している実装方法と関係ない話が突然始まったり、例をコピペしただけだと動かなかったり、「このまま使うと、別の問題を指摘されてしまうよなあ」と思うものも中にはあります。やはり他の人に安心して薦められるものになってほしいと思います。
重複している
実装方法が多いことは基本的には良いことだと思うのですが、中には同じことを言っているんじゃないのかな、と思うものもあります。ページを作る側ではなく、チェックする側の意見ですが、実装方法集は重複なく必要にして十分な数がそろっていたらな、と思うことがあります。
WAICが公開しているJIS X 8341-3:2010 試験実施ガイドライン 2012年11月版でも、「実装チェックリストの作成方法の例」として「Understanding WCAG 2.0日本語訳の「達成基準を満たすことのできる実装方法」」をもとにする話がでてきます。この実装方法はTechniques for WCAG 2.0のことですので、それが重複していると精査にも時間と手間がかかってしまいます。
適用範囲
Techniques for WCAG 2.0の中にはHTML5では使えないもの、HTML5でしか使えないものもあります。それ自体は問題ではないと思う(WCAG 2.0は特定の技術に依存していないので)のですが、HTML5に適用できる実装方法一覧を取り出したり、といったことは簡単ではありません。それぞれの実装方法に「適用(対象)」(Applicability)という欄があるのですが、この内容の揺れが結構あるので、結局は手作業でやるしかありません。
「適用」欄のばらつきを抑えて「検証」を充実させられないかなと思いました。
GitHub
Techniques for WCAG 2.0ではGitHubでPull Requestを受け付けていますが、正直わかりにくいです。
- どのブランチに対してPull Requestを送れば良いのかわかりにくい
- リポジトリのファイルからHTMLを生成する方法がわかりにくい(.travis.ymlを参照)
- 行末に空白があったり、改行やインデントがそろっていなかったりと、きれいな差分を作ることが難しい
GitHubでのPull Requestを受け付ける前に、空白やインデントの問題を修正してほしかったです。…そういう修正こそPull Requestで送ってくれ、という話なのかもしれませんが。
個々の実装方法について思ったこと
ARIA1
誤植がひどいので直しましょう。
ARIA2
ARAI2はaria-requiredを使って、入力欄が必須であることをプログラム(含む支援技術)から判断できるようにしようという実装方法です。この実装方法集が視覚的な手がかりがあった場合に限定されていますが、音による手がかりがある場合などを考えると、視覚に限定するべきではありません。
また「WAI-ARIAは草案なので~」という注記はWAI-ARIA 1.0が勧告されていますので、削除すべきです。
ARAI4とARIA5
- ARIA4: Using a WAI-ARIA role to expose the role of a user interface component
- ARIA5: Using WAI-ARIA state and property attributes to expose the state of a user interface component
ARIA4はroleを支援技術に提供しよう、ARIA5はstateとpropertyを支援技術に提供しようという実装方法です。これは人によるのかもしれませんが、私はこういったあまりにも漠然とした実装方法は不要だと思います。WCAG 2.0自体が技術によらない抽象的な書き方をしているので、サポート文書はある程度明確に書かないと、関係者をサポートできないと思うからです。
また、ARIAを使う場合に、一般的に求められることはrole、state、propertyを提供すること(roleだけとかstateだけではなく)、および、フォーカス(キーボード)を管理することだと思っていますので、roleだけ、stateとpropertyだけという実装方法は正しいとは思えません(個別の議論ではroleだけで良い場合、stateとpropertyだけで良い場合というのはありえますが)。誤解をされるよりは削除した方が良いと思います。
ARIA7
- ARIA7: Using aria-labelledby for link purpose
- H80: Identifying the purpose of a link using link text combined with the preceding heading element
ARIA7はaria-labelledbyを使って、リンクのアクセシブルな名前(支援技術から見えるオブジェクトの名前)を変更するという実装方法ですが、例1にアクセシビリティ上の大きな問題があります。
例1は、画面上では「Read more...」と書いてあるけど、それだけではスクリーン・リーダーユーザーにはリンク先が分かりにくいだろうから、直前の見出し「Storms hit east coast」と読み上げさせようというものです。この方法は全盲のユーザーがスクリーン・リーダーを使う場合には問題ないでしょうが、ほかの場合には問題が起こりえます。
ARIA 1.0には同じような問題が例として挙げられているので、引用してみます。
For example, a sighted, dexterity-impaired individual may use voice-controlled assistive technologies to access a visual interface. If an author hides visible link text "Go to checkout" and exposes similar, yet non-identical link text "Check out now" to the accessibility API, the user may be unable to access the interface they perceive using voice control.
日本語にすると次のようになるでしょうか。
例えば、目の見える上肢障害者は画面に表示される(visual)インタフェースにアクセスするために、音声制御による支援技術を使うだろう。もし制作者が画面に表示されているリンクテキスト「お支払いへ進む」を隠して、類似した、しかし同一ではない、リンクテキスト「今すぐお支払い」をアクセシビリティAPI通して提供したとしよう。この時、ユーザーは音声制御で認識しているインターフェースにアクセスできないだろう。
例1の場合には、「もっと読む」と表示されているものを音声で操作するために「嵐が東海岸を襲う」と入力しなくてはならなくなってしまいます。
例1以外の例も画面に表示されているテキストと支援技術から認識できるテキストが異なるので微妙なのですが、例1の問題ぶりは群を抜いています。問題のある例は削除すべきです。
なお、ARIA7以外にもリンクテキストとその直前の見出しを組み合わせてリンク先の情報を伝える実装方法(H80)があります。WAICが公開しているアクセシビリティ・サポーテッド情報(2014年6月版)によると、最近のスクリーン・リーダーの多くで、リンクからフォーカスを移動させることなく直前の見出しを読み上げることができます。見出しとリンクテキストを組み合わせてリンク先の情報を伝える場合に、無理にaria-labelledbyを使う必要はないと私は思います。
ところで、H80がSufficient Techniqueになっていない件はWAIC的にどうなのか、私、気になります。
H39とH73
- H39: Using caption elements to associate data table captions with data tables
- H43: Using id and headers attributes to associate data cells with header cells in data tables
- H63: Using the scope attribute to associate header cells and data cells in data tables
- H73: Using the summary attribute of the table element to give an overview of data tables
- F46: Failure of Success Criterion 1.3.1 due to using th elements, caption elements, or non-empty summary attributes in layout tables
H39はデータテーブルでcaption要素を使うという実装方法で、H73はデータテーブルでsummary属性を使う、という実装方法です。
どちらもデータテーブルの話をしているのに、「検証」(Tests)には、「レイアウトテーブルでcaption要素/summary属性が使われていないことをチェックする」云々という話がでてきます。レイアウトテーブルでcaption要素やsummary属性を使わないことはF46にまとめられていますので、H39とH73からはレイアウトテーブルの話は削除すべきです。なお、H63ではデータテーブルでscope属性を使う話がでていますが、「検証」では「それぞれのデータテーブルについて」と、シンプルにまとめられています。
H43のデータテーブルでheaders属性を使うという実装方法の「検証」でも、レイアウトテーブルかどうかのチェックがありますが、F46でのheaders属性の扱いがあいまいなので、こちらはF46を調整する必要があるように思います。
SCR2
- SCR2: Using redundant keyboard and mouse event handlers
- SCR20: Using both keyboard and other device-specific functions
- SCR29: Adding keyboard-accessible actions to static HTML elements
- SCR35: Making actions keyboard accessible by using the onclick event of anchors and buttons
SCR2はキーボードとマウスのイベントハンドラ―をそれぞれ指定しようという実装方法、SCR20はキーボードと他のデバイス固有の機能を使おうという実装方法です。
内容はどちらもキーボードと他のデバイス固有のイベントを両方使うというものですので、より一般的なSCR20を残してSCR2は削除すべきです。
似たような実装方法にSCR29があります。これは、div要素やspan要素にtabindex="0"を付与したうえで、clickとkeypressイベントを両方処理しようという実装方法です。こちらは独立した実装方法になっていても良いと私は思っています。というのも、a要素やbutton要素など(HTML5が言うところの「activation behavior」が定義された要素)ではclickイベントだけ処理すれば良いという話(SCR35)があり、場合分けすると3つの実装方法が必要だと思うためです。
- activation behaviorが定義された要素(a要素やbutton要素)
- activation behaviorを起こすイベントの処理:SCR35(clickイベントを処理すればOK)
- activation behaviorを起こさないイベントの処理:SCR20(各デバイスのイベントを処理しなきゃ)
- activation behaviorが定義されていない要素(div要素やspan要素)
- activation behaviorが定義された要素だったら、activation behaviorを起こすイベントの処理:SCR29(各デバイスのイベントを処理しなきゃ…SCR35へ誘導)
- activation behaviorが定義された要素だったとしても、activation behaviorを起こさないイベントの処理:SCR20(各デバイスのイベントを処理しなきゃ)
F17
- F17: Failure of Success Criterion 1.3.1 and 4.1.1 due to insufficient information in DOM to determine one-to-one relationships (e.g., between labels with same id) in HTML
- F62: Failure of Success Criterion 1.3.1 and 4.1.1 due to insufficient information in DOM to determine specific relationships in XML
- F68: Failure of Success Criterion 1.3.1 and 4.1.2 due to the association of label and user interface controls not being programmatically determined
- F77: Failure of Success Criterion 4.1.1 due to duplicate values of type ID
- F90: Failure of Success Criterion 1.3.1 for incorrectly associating table headers and content via the headers and id attributes
F17は、F17以外にも同じことを言っている不適合事例が多い、不適合事例です。F17は例として3つの問題を挙げています。
- id属性値がユニークではない問題
- for属性などで、id属性値や他の識別子への参照が正しくない場合
- accessskey属性がユニークでない問題
このうちid属性値がユニークでない場合はF62として既にありますし、識別子への参照が正しくない場合はF68として既にあります*2。
なのでF17が存在している理由はほとんどないありませんが、accesskey属性がユニークではない話は他の不適合事例にはでてきません。F17はaccesskey属性がユニークかどうかの話に絞って書きなおすべきです。
F41
- F40: Failure of Success Criterion 2.2.1 and 2.2.4 due to using meta redirect with a time limit
- F41: Failure of Success Criterion 2.2.1, 2.2.4, and 3.2.5 due to using meta refresh with a time-out
F40は<meta http-equiv="referesh">を使って別のページにリダイレクトする際の問題、F41は<meta http-equiv="referesh">を使って同じページを再読み込みされる際の問題です。
F41には例が2つありますが、2つ目の例はF40の問題(別ページにリダイレクトさせている)ですので、削除すべきです。関連する実装方法のSVR1もF40に関連し、F41には関連していないので削除すべきです。
また、F41の試験方法では、0秒で再読み込みさせている場合には不適合になりませんが、実際にはユーザーに再読み込みを停止させる方法を提供せずに、自動的に再読み込みしている時点で問題があります*3。なので、「0秒より長い」ではなく「0秒以上」にあたらめるべきですし、F41の名前からも「タイムアウト」を取るべきです。
F42
- F42: Failure of Success Criterion 1.3.1 and 2.1.1 due to using scripting events to emulate links in a way that is not programmatically determinable
- F54: Failure of Success Criterion 2.1.1 due to using only pointing-device-specific event handlers (including gesture) for a function
- F59: Failure of Success Criterion 4.1.2 due to using script to make div or span a user interface control in HTML without providing a role for the control
F42は、プログラムからリンクとして認識できない方法でリンクをエミュレートしている、という不適合事例です。div要素のclickイベントなどでlocation.hrefを書き換えているような場合が該当します。
この不適合事例には2つの観点があります。1つはdiv要素のclickイベントなどを使うとキーボードで操作できない、という話です。これはF54のポインティングディバイス固有のイベントハンドラ―しか使っていないという不適合事例と同じです。
もう1つは、たとえキーボードで操作できたとして、div要素などを使っているとブラウザーや支援技術からはリンクだと認識できない、という話です。これはF59のroleを提供せずにdiv要素やspan要素でユーザーインタフェースコンポーネントを作っている不適合事例と同じです。F59ではユーザーインタフェースコンポーネントの例としてリンクも挙げられています。
F42として独立させる理由はありませんので削除すべきです。
F48
- F33: Failure of Success Criterion 1.3.1 and 1.3.2 due to using white space characters to create multiple columns in plain text content
- F34: Failure of Success Criterion 1.3.1 and 1.3.2 due to using white space characters to format tables in plain text content
- F48: Failure of Success Criterion 1.3.1 due to using the pre element to markup tabular information
- H51: Using table markup to present tabular information
F48はpre要素を使って表形式の情報をマークアップしている、という不適合事例です。確かにこういう実装は問題なのですが、F34(空白文字を使って表をフォーマットしている)との違いがわかりません。また、F33(空白文字を使って複数カラムを作っている)にはpre要素版はありません。F34とF48をそれぞれ立てる必要はありませんので、一般的なF34を残してF48は削除すべきです。
F55
F55は、onfocusでthis.blur()をしているという不適合事例です。
F55の例3は例2とほぼ同じです。この不適合事例ではblur()することが問題なので、その意味では例2と例3は変わりません。なので、例3は削除すべきです。
F68
F68はフォームコントロールに視覚的なラベルがあるのに、フォームコントロールと関連づけられていない、という不適合事例です。視覚的なラベルが使われている場合、と繰り返し述べているにも関わらず、F58には視覚的なラベルが使えない話がでてきます。視覚的なラベルが使えない場合の話はF68からは削除すべきです。
おわりに
Techniques for WCAG 2.0について感じたことの「重複している」に対するコメントが多くなってしまいました。実際にはARIAまわりなどは足りないように思いますので、今後実装方法が増えていくでしょうし、増えないと困ります。
また、今回は突っ込みをする会でしたのでネガティブな話が多いですが、私はTechniques for WCAG 2.0がより使われるようになってほしいと思っています。…そうすれば、人に訊かれた際にも「これを読んでおいて」で済みますから。
縦書きと代替テキストの表示
最近では多くのブラウザーが縦書きに対応するようになりました(ただしFirefoxは除く)。CSSで縦書きを扱えることのメリットの1つは、縦書き部分を画像ではなくテキストで表現できることだと思いますが、画像を使わなくてはならない場合もあると思います。ですが、多くのブラウザーでは縦書きの中にある画像の代替テキストは、縦書きとしては表示されません。
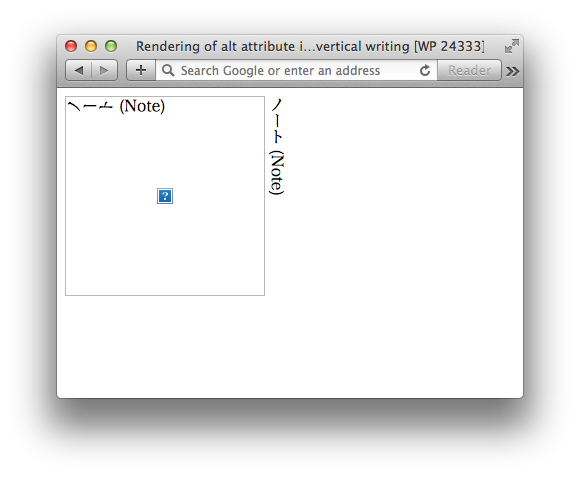
ノート (Note)
SafariやGoogle Chromeでは、縦書きの中にある画像の代替テキストは、縦書きのテキストを反時計回りに90°倒したように表示されます。水平方向(左から右)に文字が進んでいると考えても、文字の向きがおかしいです(反時計回りに90°倒れている)。
Internet Explorer 11では、縦書きの中にある画像の代替テキストは、横書きで表示されます。文字の向きがおかしくなることはありませんが、不自然なように私は思います。またwidthやheightが指定されていない場合、代替テキストが収まるようにimg要素の大きさを決めているため、縦長の画像がくる場所に横長のimg要素が表示されて、見た目が残念なことになる、ということもおこりそうです。例えば、縦に1行テキストが書かれた画像が表示される場所に、横1行の代替テキストが表示される、といった場合です。
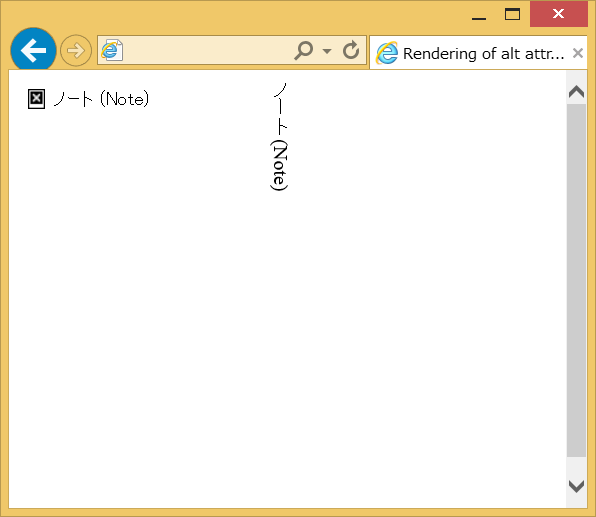
代替テキストの表示も含めて、ブラウザーの縦書き対応が進むことを期待します。
MathMLとアクセシビリティAPI
数式のアクセシビリティには様々な切り口が考えられますが、ここではMathMLとアクセシビリティAPIについて見てみます。
アクセシビリティAPIを使ったアプローチは大きく2つあります。アクセシビリティAPIに数式を表現するための仕組みを設ける方法と、既存のアクセシビリティAPIの中でなんとかする方法です。
数式用アクセシビリティAPI
アクセシビリティAPIに数式を表現するための仕組みを設け、ブラウザーはその仕組みにそって数式を表現し、支援技術はその仕組みから情報を得るというアプローチです。正攻法と言えるアプローチです。
OS XとiOSのアクセシビリティAPIには数式用のRolesやPropertiesがあります。SafariはこのアクセシビリティAPIに対応しており、VoiceOverを使ったMathMLの読み上げなどが行えます。iOS 7には数式をNemeth点字(アメリカ合衆国で一般的な数式用の点字)で出力するオプションもあるようです(が、私は点字が読めないため、ちゃんと機能しているのか不明です)。
- WebAccessibilityObjectWrapperMac.mm
- The Journey Toward Braille: Potential and Limitations of using Braille with iDevices
このアプローチのメリットは、アプリケーションが数式用のAccessiblity APIに対応すれば、内部的に数式をどう扱っていようとも、支援技術は追加の対応なしに数式をサポートできる、ということです。
最近、FirefoxもOS X版ではこのアクセシビリティAPIへの対応を進めています。
- MathML Accessibility | Air Mozilla
- Accessibility/MathML - MozillaWiki
- 1001641 – Provide equivalent support for MathML as WebKit for NSAccessibility
OS XやiOSではブラウザー・アプリケーションのサポートが進めば、支援技術から数式を理解しやすくなるでしょう。
非数式用アクセシビリティAPI
他のプラットフォームではアクセシビリティAPIに数式用のオブジェクトがない場合がほとんどです。ですが、アクセシビリティAPIのオブジェクトは要素型や属性の情報を含めることができます。そのため、支援技術がアクセシビリティAPIのオブジェクトから要素型や属性の情報を取り出して、MathMLとして処理し、ユーザーに情報を伝えるアプローチも考えられます。
NVDAのJames Teh氏は、数式を処理するライブラリはMathMLを受け付けるようにできているので、ブラウザーはMathMLの情報をそのまま支援技術にわたすよう、MozillaのBugzillaでコメントしています(916419 – Expose MathML as a hierarchical accessible tree)。
また、彼はプロトタイプも作成しているようです。
I now have an early prototype of #NVDASR Firefox MathML support which can speak, braille & hierarchically navigate the quadratic formula!
— James Teh (@jcsteh) 2013, 9月 24このアプローチではアプリケーションと支援技術の双方がMathMLに対応する必要があります。今現在、支援技術が数式に対応するには、何らかの処理を追加する必要があるでしょう。その際、MathMLに対応しておけば大丈夫という状況になれば、このアプローチは有効なのですが…。